Kapitola 8 · Za hranicí labu · 6 min čtení
Na této stránce28
Kam dál
Základy máš. Zbytek je menu, ne povinnost. Vezmi si jednu věc po druhé, zkus ji, ostatní nech na potom.
Testování, pořádně
Tři postupy, které stojí za vyzkoušení — od lidí, co se o nich veřejně hádali.
Tracer bullet — jeden test před feature
Než cokoliv postavíš, napiš jeden end-to-end test, který selže, protože feature ještě neexistuje. Ověříš, že propojení funguje — request dorazí do kontroléru, do servicy, do DB — a pak iteruješ k zelenému.
Metaforu razí Andy Hunt a Dave Thomas v The Pragmatic Programmer. Vystřelíš pár raket, díváš se, kam dopadly, upravíš mířidla. Jejich rozhovor na Artimě o tracer bullets ↗ vysvětluje, odkud metafora pochází a k jaké disciplíně vede.
Napiš failing end-to-end test pro POST /api/items endpoint, který vytvoří item a vrátí 201. Endpoint ještě neexistuje — jenom to dotáhni tak, ať test selže na správném řádku.
Stav, dokud neprojde. Integraci si tentokrát budeš pamatovat.
TDD — red, green, refactor
Test první, implementace druhá, refactor třetí. Tři samostatné prompty, tři samostatné diffy.
Kent Beck tu praktiku pojmenoval v knize Test-Driven Development: By Example. Kolem TDD se ale roky vedou spory. Série Is TDD Dead? ↗ z roku 2014 mezi Beckem, Martinem Fowlerem a DHH je pořád nejlepší mapa toho, kde TDD pomáhá, kde škodí a co vlastně „TDD" znamená. Přečti si to jednou a vyber si vlastní postoj.
Napiš failing test pro funkci slugify(input: string), která zvládá diakritiku a opakované mezery. Použij naše stávající test setup.
Pak:
Nech test projít. Minimální implementace.
Pak:
Zrefaktoruj. Drž testy zelené. Hledej duplikaci a nejasná pojmenování.
Tři diffy, tři kontroly, tři správné věci.
TDD je místo, kde si agenti zaslouží plat
Beck sám nedávno: TDD je pro AI agenty „superpower“. Rozhovor s Beckem v Pragmatic Engineer ↗ stojí za tu hodinu — Builder.io mechaniku shrnul dobře: „všechno, co z TDD dělá pro lidi otravnou dřinu, z něj pro AI agenta dělá perfektní workflow ↗“. Napiš testy, dej je agentovi, ať iteruje k zelenému — bez zranění ega, které si lidi odnášejí, když se jejich kód pořád odráží od červeného.
Protipól, stejný rozhovor: agenti občas testy smažou, aby „prošly“. Kontroluj diff. V review přišpendli soubory s testy.
Mutační testování — zkontroluj samotné testy
Každý projekt se jednou zeptá: chrání mě test suite doopravdy? Na to odpovídá mutační testování. Nástroj udělá malé změny v kódu — přehodí porovnání, vyhodí return — a pustí tvoje testy. Jestli projdou, netestovaly to, co sis myslel.
Stojí to za pozornost. Ne za to, abys na tom trval, dokud nemáš reálnou suite, kterou by šlo mutovat.
Review od agenta
Agentům nevadí číst tvůj kód. Můžou ho procházet na každém PR, na každém commitu, před každým mergem. Pět, které stojí za to znát:
Claude Code /code-review
Součást Claude Code. Spusť /code-review na libovolném diffu — vypíše chyby správnosti. Přidej úroveň úsilí (/code-review high) pro hlubší průchod. Přidej --comment a nálezy se přidají jako inline komentáře na GitHub PR. Přidej --fix a Claude nálezy rovnou zapíše do working tree — zjednodušení, znovupoužití, efektivita. /simplify je teď alias pro /code-review --fix.
Jiný job než /security-review: code-review hledá chyby správnosti, security-review hledá zranitelnosti. Na PR, které na tom záleží, spusť oboje.
Claude Code /security-review
Součást Claude Code. Skenuje aktuální diff na SQL injection, XSS, auth díry, nebezpečnou práci s daty, problémy v závislostech — s hodnocením závažnosti a odfiltrováním falešných poplachů. Přizpůsobíš zkopírováním security-review.md do .claude/commands/. Zdroj: anthropics/claude-code-security-review ↗.
V CI stejný engine běží jako GitHub Action přes anthropics/claude-code-action ↗ — chytí problémy ještě předtím, než se na PR podívá člověk.
GitHub Copilot Autofix
Součást GitHubového code scanningu. Když CodeQL ohlásí alert, LLM navrhne fix přímo v PR — přijmeš, upravíš, nebo zamítneš. Na veřejných repech zdarma, na privátních v rámci licence Code Security. Podporuje C#, C/C++, Go, Java/Kotlin, Swift, JS/TS, Python, Ruby, Rust. Dokumentace Copilot Autofix ↗.
Semgrep Assistant + MCP
Semgrep ↗ je rychlý statický analyzátor. Jeho MCP server ↗ napojí scanner do Claude Code a dalších agentů: agent spustí sken, přečte nález, navrhne fix, sken znova — uzavřená smyčka. Dobré, pokud tvoje CI Semgrep pravidla už používá.
Snyk DeepCode AI
Snyk DeepCode AI ↗ kombinuje symbolický engine taint analýzy s neural modelem trénovaným na milionech řádků. Symbolická část omezuje, co LLM smí navrhnout — malé cílené fixy, ne přepisování. Stojí za zvážení, pokud už codebase v Snyk žije.
Amazon Q Developer code reviews
Q Developer ↗ kontroluje kódy na bezpečnost a kvalitu — SAST, SCA, AWS best practices — a co umí, opraví sám. Nejlepší fit, když už na AWS jedeš a chceš mít nálezy vedle ostatních Q workflowů.
Vyber si jeden, který sedí k místu, kde tvůj kód žije. Dva najednou je v pohodě; pět je šum.
LLMs pro security — aktuální nástroje
Dva nástroje, co stojí za zmínku. Oba mění krajinu, oba mají háček v přístupu.
AWS Security Agent
AWS Security Agent ↗ šel do GA na konci března 2026. Autonomní penetration testing, 24/7, $50 za task-hour — zhruba $1 200 za plný test aplikace. Jiná třída nástroje než code review v Q Developeru: Q hlásí chyby ve zdrojáku; Security Agent se snaží rozbít běžící aplikaci způsobem, jakým by to dělal lidský pentester.
Čistý pitch: pentest na každý release místo jednoho za rok.
GPT-5.4-Cyber
Cybersecurity verze GPT-5.4 od OpenAI ↗ má volnější pravidla odmítání pro legitimní security práci — vulnerability research, reverse engineering binárek, analýza malwaru. Přístup je omezený. Musíš se přihlásit do programu Trusted Access for Cyber, projít verifikací, a teprve pak ti model zapnou. Firmy přes svého account repa; jednotlivci na chatgpt.com/cyber.
Zmiňuju ho, protože o něm uslyšíš. Čekat na něj ne — na denní defenzivní práci s aplikačním kódem pokrývají nástroje výš skoro všechno, co skutečný tým potřebuje.
Kde začít, když začínáš teď
/security-review na každý commit. claude-code-action na každý PR. Jeden dedikovaný nástroj (Semgrep, Snyk, nebo Q Developer) v CI jako SAST vrstva. AWS Security Agent přidej, až budeš mít něco nasazeného, co stojí za to napadnout. GPT-5.4-Cyber přeskoč, dokud nebudeš mít konkrétní defenzivní use-case, kvůli kterému stojí za to procházet verifikací.
Bezpečnost, která nezmizí
Nástroje pomáhají. Tvar problému ale nesmažou.
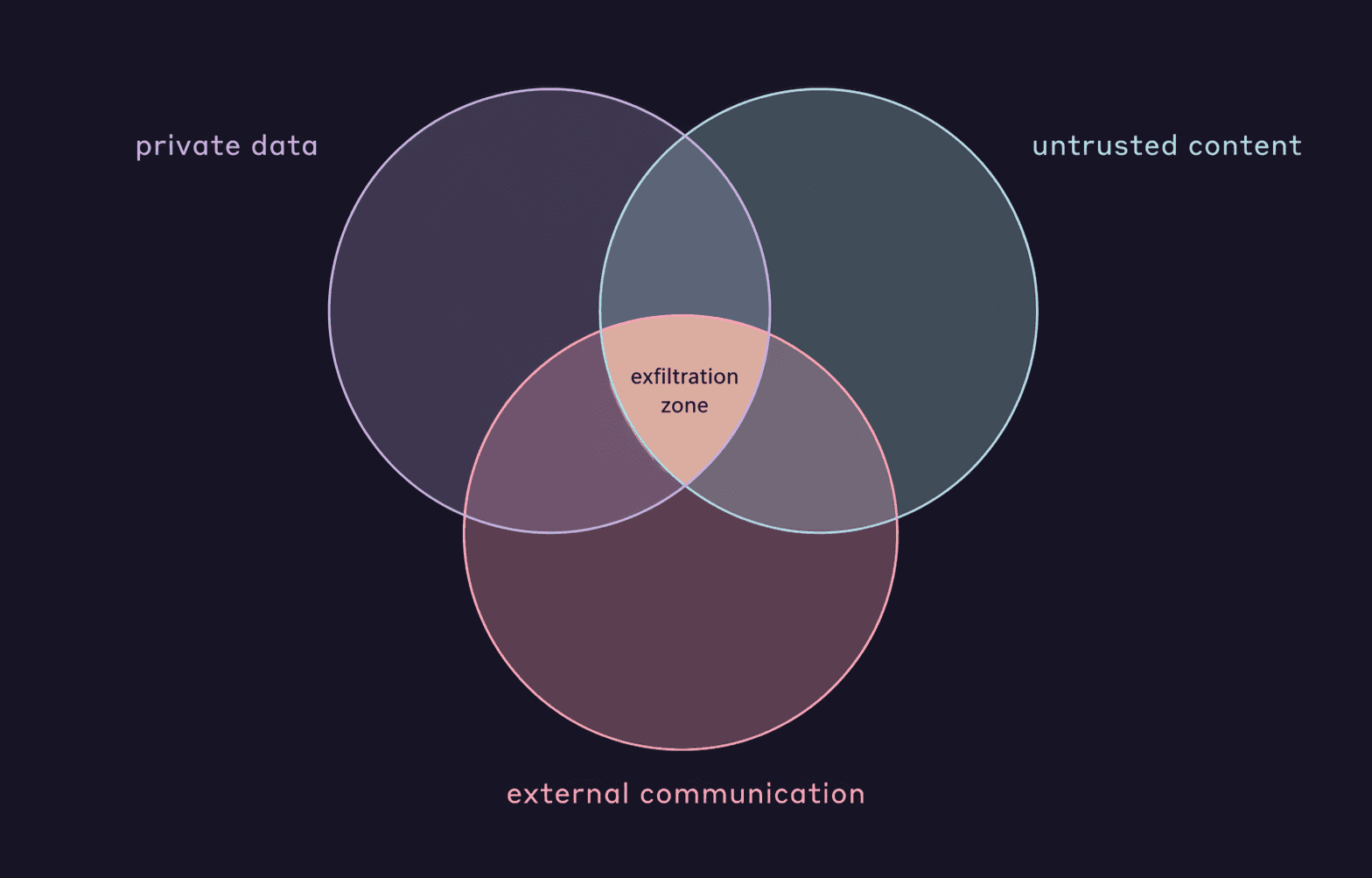
Simon Willison pojmenoval lethal trifecta ↗ — tři podmínky, které společně umožní útočníkovi vytáhnout tvoje data přes agenta:
- Přístup k privátním datům — tvoje repo, tvoje tokeny, tvoje zákaznická data.
- Vystavení nedůvěryhodnému obsahu — GitHub issue, scrapovaná stránka, mail, výstup z MCP toolu.
- Externí komunikace — jakýkoliv kanál, přes který může agent ven.
Když jsou všechny tři aktivní, útočník, který umí vpravit instrukce do nedůvěryhodného obsahu, obvykle donutí agenta privátní data poslat ven.
Korny Sietsmův Agentic AI and Security ↗ na martinfowler.com framework rozšiřuje do praktických mitigací: rozděl úkoly tak, aby každý podúkol odstranil aspoň jednu nohu trifecty; pouštěj LLM v sandboxovaných kontejnerech; drž malé kroky, které si člověk může zkontrolovat.
Praktický postoj:
- Každé MCP, které přidáš, projdi na trifectu. Většina MCP třetích stran stahuje nedůvěryhodný obsah.
- Nepouštěj agenta s volnou rukou na soubory s testy — Beckův protipól („agenti testy mažou") je reálný.
- Na cokoliv kolem auth, secrets, nebo migrací kontroluj diff.
Agent je rychlý. Lidi drží hranici.
Sandboxing
/sandbox je způsob, jak tu hranici postavit pořádně. Obalí každý bash příkaz, který Claude pouští — a všechny subprocesy, které tyhle příkazy spustí (npm install, kubectl, terraform, cokoliv) — vrstvou izolace na úrovni OS. Zápis do filesystemu je defaultně omezen na pracovní adresář. Síťový provoz jde přes proxy, která pustí jen schválené domény.
Přímá mitigace trifecty. Sandbox defaultně odstraní nohu externí komunikace. I když útočník vpraví instrukce přes MCP nebo scrapovanou stránku, odchozí požadavek na evil.com umře na proxy. Zmenšíš dopad, aniž bys spoléhal, že Claude injekci odhalí sám.
Napiš /sandbox v session a vyber režim:
- Auto-allow — sandboxované příkazy se neptají na povolení. Anthropicova interní data ukazují o 84 % méně promptů.
- Regular permissions — stejná izolace, standardní permission flow.
Sandboxing je nezávislý na režimech oprávnění z kapitoly 4. Auto-allow sandbox může běžet, i když jsi v „Ask permissions" — bash příkazy uvnitř hranice běží bez dotazu, zatímco editace souborů se pořád ptá.
Podpora platforem. macOS funguje out-of-the-box přes Seatbelt. Linux a WSL2 potřebují nejdřív sudo apt install bubblewrap socat. WSL1 a nativní Windows zatím nefungují.
Pro firemní nasazení jsou důležité tyhle flagy v managed settings:
sandbox.failIfUnavailable: true— Claude Code odmítne běžet, když sandbox nestartuje. Žádný tichý fallback.allowUnsandboxedCommands: false— vypne escape hatch, přes který by jinak Claude znovu spustil padající příkaz mimo sandbox.sandbox.network.allowManagedDomainsOnly: true— na síť se dostanou jen admin-schválené domény; uživatelé můžou allowlist rozšiřovat, ale admin restrikce neodstraní.
Dohromady to ze sandboxu udělá bezpečnostní gate, ne jen rozumný default.
Co nepokrývá. Jen bash subprocesy. Read, Edit, Write, WebFetch jdou přes permission systém, ne sandbox. Computer use běží na tvém reálném desktopu. A filtrování na úrovni domén není inspekce paketů — široký allowlist jako github.com pořád umožní exfiltraci přes gisty a issues. Obrana do hloubky, ne totální řešení.
Automatizace
Hooky
Spouštěj skripty automaticky před nebo po událostech Claude. Auto-format při uložení, blokování commitů do mainu, Slack notifikace po doběhnutí dlouhého úkolu. Konfigurace v settings.json nebo v hooks/hooks.json pluginu.
Zkus tohle první: přidej PostToolUse hook, který pustí tvůj linter po každé editaci. Jeden řádek konfigurace, jeden manuální krok méně.
→ Hooks docs ↗ · katalog událostí v kapitole 9.7
Claude v CI
Pusť Claude v GitHub Actions přes anthropics/claude-code-action@v1. Spouští ho @claude mention v issues nebo PR; fungují i cron a události. Automatické review PR, triage issues, generování changelogů, otevírání follow-up PR.
Zkus tohle první: v libovolném repu spusť /install-github-app v Claude Code — provede tě nastavením. Pak v libovolném otevřeném issue napiš @claude přidej do README sekci o environment variables.
→ Claude Code GitHub Actions ↗
Smyčky a naplánované běhy
Dlouhotrvající úkol se může spouštět každých N minut nebo podle plánu. „Každé ráno zkontroluj main, jestli nepadá nějaký test, a otevři fix PR.“ „Každý večer shrň, co se mergovalo, a pošli do Slacku“.
/loop pustí příkaz v opakujícím se intervalu. /schedule (v Heart of Gold toolkitu) vytvoří remote agenta s cronovým plánem. Shadow tasky dělají svoji práci na pozadí, aniž by narušily tvoji aktuální konverzaci.
Zkus tohle první: /loop 5m zkontroluj, jestli nepadají nějaké testy, a nahlas. Nech to běžet, zatímco pracuješ na něčem jiném.
Agenti, kteří se učí napříč sessionami
Claude Code se mezi konverzacemi resetuje. CLAUDE.md pomáhá; /compound ve smyčce Compound Engineering pomáhá víc. Obojí ale vyžaduje, abys nezapomněl si to zapsat.
altk-evolve ↗ (IBM Research, Apache 2.0) krok paměti automatizuje. MCP server nabírá trajektorie — co fungovalo, co ne — do vektorového storu a do nových sessionů vpravuje relevantní poučení. Hlášeno +8.9 bodů na AppWorld benchmarku, +74 % na těžkých víc-krokových úkolech. Nasadíš ho do Claude Code, Codexu i Boba.
Zkus to, až budeš měsíc v Compound Engineering a pořád budeš cítit, že napříč projekty opakuješ stejné fixy. Přesně na tenhle problém je altk-evolve navržený.
Lidi, které stojí za to sledovat
Pole se hýbe rychle. Pět hlasů, které stojí za to dlouhodobě sledovat.
- Simon Willison ↗ — nejspolehlivější signál o tom, co LLM skutečně umí, o bezpečnosti agentů, a o tom, kde hype praská. Pojmenoval „prompt injection" i „lethal trifecta". Poctivé výhrady, malé funkční ukázky. Čti blog.
- Korny Sietsma ↗ — bezpečnost agentních systémů z pohledu agilního inženýra. Jeho Agentic AI and Security ↗ na martinfowler.com je aktuálně nejpřehlednější vstup do té útočné plochy.
- Tanya Janca ↗ (SheHacksPurple) — autorka knih Alice and Bob Learn Application Security a Alice and Bob Learn Secure Coding. Učí vývojáře, ne security týmy. Pokud je tvůj reflex „security je věc někoho jiného", tohle je reset.
- Daniel Miessler ↗ — týdenní newsletter Unsupervised Learning ↗ pokrývá AI, security, a jejich průsečík. Dobré na to, aby ses k trendům dostal dřív, než ti přistanou v inboxu jako direktiva.
- Laurie Williams ↗ — NC State, výzkum zabezpečení dodavatelských řetězců softwaru a DevSecOps praktik podpořený NSF. Akademická důslednost, praktikující publikum. Její publikace sleduj, když tě téma (SBOM, útoky přes závislosti, pair programming) zajme natolik, abys chtěl jít hlouběji.
Pět jmen, pět URL. Hodina týdně napříč nimi stačí, aby ses neztratil.
Pusť /powerup — zabudovaná prohlídka
Anthropic vydal v dubnu 2026 interaktivní onboarding přímo v Claude Code. Napíšeš /powerup a dostaneš deset animovaných průchodů po 3 až 10 minutách — po funkcích, které většina lidí přehlédne: @-zmínky souborů, plan a auto režimy, rewind, úkoly na pozadí, CLAUDE.md, MCP, skilly a hooky, subagenti, remote control, a dial modelu.
Devět z deseti se kryje s kapitolami, které jsi právě četl — /powerup je animovaný doprovod tohohle průvodce. Jedinou skutečně novou věc, kterou tenhle lab nepokryl, je /tasks pro práci na pozadí — rozjedeš dlouhý běh, pracuješ dál a výsledek si vyzvedneš později.
Stojí za večer. Počítadlo postupu („0/10 unlocked") se mezi sezeními resetuje, takže jestli chceš, aby se power-up počítal, dokonči ho před zavřením terminálu.
Tenhle lab je na GitHubu
Celý tenhle průvodce — web, kapitoly, ukázky, doprovodný skill — je open source na github.com/ondrej-svec/claude-code-lab ↗. Pokud něco nesedělo, pokud je čeština vedle, pokud máš pattern, který stojí za přidání: otevři issue nebo PR. Hvězda pomáhá — je to signál, abych to dál zlepšoval.
Praxe: pokračuj se svou ukázkou
Procházíš lab popořadě? Vezmi, co tě tahle kapitola naučila, k ukázce, se kterou jsi začal v kapitole 2 — nebo rovnou ke svému vlastnímu codebase, kde to sedne hlouběji.
- Pusť
/security-reviewve složce projektu. Přečti si, co ti to vyhodí — neber to jako pass/fail, ale jako mapu toho, co by zvednul lidský reviewer. U ukázek čekej malý seznam; u vlastního repa je delší a zajímavější. - Přidej tracer-bullet test pro endpoint, který jsi napsal v kapitole 2. Prompt: „Napiš failing end-to-end test pro
GET /health, který ověří 200 a{ ok: true }.“ Nejdřív ať test padá, pak ho nech projít. Máš reálný test na reálnou route. - Volitelně: forkni repo (nebo nainstaluj ve vlastním) a napoj
anthropics/claude-code-action@v1na default branch. Na příští PR tagni@claudea koukni, jak to auto-review proti tvémuCLAUDE.md.
Když to funguje: tvoje ukázka má security scan, který sis přečetl, tracer-bullet test, co prochází, a volitelně Claude reviewera, který sleduje každý PR. Tak vypadá harness v praxi — ověřování bez očí na každém diffu. Stejné pohyby vezmi zítra na skutečný projekt.
Poslední slovo
Nic tady není povinné. Ber tuhle kapitolu jako save point. Vrať se, až nahmatáš limity toho, co víš, a vyber si jednu věc na vyzkoušení.
Hodně štěstí. Bav se. Postav něco, co se skládá samo na sebe.